|
|---|
|
|---|
The purpose of the Patent Mining Task is to create technical trend maps from a set of research papers and patents. Figure 1 shows an example of a technical trend map that is created from research papers and patents. In this map, research papers and patents are classified in terms of elemental technologies and their effects.
| Effect 1 | Effect 2 | Effect 3 | ||
|---|---|---|---|---|
| Technology 1 | [AAA 1993] [US Pat. XX/XXXX] |
[BBB 2002] | ||
| Technology 2 | [CCC 2000] | |||
| Technology 3 | [US Pat. YY/YYYY] | [US Pat. ZZ/ZZZZ] [USP WW/WWWW] |
To create technical trend maps, the following two steps are required.
For each of these steps, we will conduct the following two subtasks.
In the following, we describe the details of these subtasks.
In the same way, Japanese, English, and Cross-lingual Subtasks are conducted in NTCIR-8.
In this subtask, each system is requested to extract expressions of element technologies and their effects from research papers and patents. Figure 2 is an example of the data for this subtask. In this example, "Technology" and "Effect" tags are annotated to an elementary technology and its effect in the text. In the "Effect" tag, "Value" and "Attribution" tags are also annotated. We will conduct as a pilot subtask, because this is a new subtask, and we need to discuss about a task design. The following subtasks are conducted.
Figure 2 An example of a data for the Subtask of Technical Trend Map Creation
[Japanese]
PM磁束制御用コイルを設けて<Technology>閉ループフィードバック制御</Technology>を施すため、<Effect><Attribution>電力損失</Attribution>を<Value>最小化</Value></Effect>できる。
[English]
Through <Technology>closed-loop feedback control</Technology>, the system could <Effect><Value>minimize</Value> the <Attribution>power loss<Attribution> </Effect>.
Figure 3 is another example, in which "Value" is a numerical expression.
Figure 3 Another example for the Subtask of Technical Trend Map Creation
[English]
<Technology>CRF-based approach</Technology> obtained a <Effect><Attribute>precision</Attribute> of <Value>0.935</Value></Effect>.
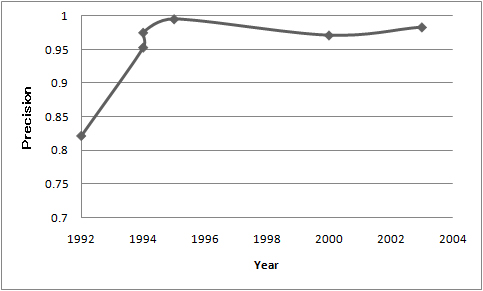
If precision scores are extracted from a set of technical documents in a specific field, such as morphological analysis or syntactic analysis, and put them on a graph, we can understand changes of temporal statistical data. Figure 4 is an example of output, which is generated from a set of research papers in morphological analysis field. In this graph, x-axis and y-axis indicate "publication year of each paper" and "precision scores of morphological analysis systems", respectively. This study is considered as a kind of summarization of trend information, which was conducted as the MuST Task [Kato et al., 2008] in the NTCIR-7.
For a researcher in a field with high industrial relevance, retrieving research papers and patents has become an important aspect of assessing the scope of the field. Examples of these fields are bioscience, medical science, computer science, and materials science. In fact, the development of an information retrieval system of research papers and patents for academic researchers is central to the Intellectual Property Strategic Programs for 2006, 2007, and 2008 of the Intellectual Property Strategy Headquarters in the Cabinet Office, Japan.
In addition, research paper searches and patent searches are required by examiners in government Patent Offices, and by the intellectual property divisions of private companies. An example is the execution of an invalidity search among existing patents or research papers, which could invalidate a rival company's patents or patents under application in a Patent Office.
However, the terms used in patents are often more abstract or creative than those used in research papers, to try to widen the scope of the claims. Therefore, the Patent Mining Task aims to develop fundamental techniques for retrieving, classifying, and analyzing both research papers and patents.
In previous NTCIR Workshops, Patent Classification Subtasks were conducted [Iwayama, 2005][Iwayama, 2007]. In these subtasks, participants were asked to classify Japanese patent applications in terms of the File Forming Term (F-term) system, which is a classification system for Japanese patent documents. Here, we are focusing on the classification of research papers in addition to patents, and we conducted the Patent Mining Task in NTCIR-7 [Nanba, 2008a][Nanba, 2008b]. The aim of the Patent Mining Task in NTCIR-7 was the classification of research papers written in either Japanese or English in terms of the International Patent Classification (IPC) system. In NTCIR-8, we will continue this task. In addition to this subtask, we also start a new subtask of technical trend map creation.
Application form is available at this page.(to appear)
Subtask of Research Papers Classification
Preparation Call for participation 2009.5.15 Data release As needed. Dry run Topic release 2009.10.152009.10.16Submission deadline 2009.11.152009.11.16Evaluation release 2009.11.22 Formal run Topic release 2009.12.22 Submission deadline 2010.01.22 Evaluation release 2010.01.29 Preparation for meeting Paper for the proceedings due 2010.04.01 Camera-ready paper for the proceedings due 2010.05.15 Workshop meeting at Tokyo 2010.6.15-18
Subtask of Technical Trend Map Creation
Preparation Call for participation 2009.5.15 Data release (research papers) 2009.10.01 (1) Data release (patents) 2009.10.15/31 (2) Dry run Topic release 2009.11.15 Submission deadline 2009.12.15 Evaluation release 2009.12.22 Formal run Topic release 2010.01.22 Submission deadline 2010.02.22 Evaluation release 2010.03.01 Preparation for meeting Paper for the proceedings due 2010.04.01 Camera-ready paper for the proceedings due 2010.05.15 Workshop meeting at Tokyo 2010.6.15-18
Last modified on May 15, 2009